Việc tìm kiếm trong hệ thống tệp hoặc xử lý văn bản có thể trở nên phức tạp. Bạn có bao giờ gặp khó khăn trong việc tìm kiếm cụ thể hay chính xác một thứ gì đó không? Hoặc đôi khi kết quả quá “nhiễu” và không liên quan? Regex (Regular Expressions) – hay còn gọi là Biểu thức chính quy – có thể giải quyết những vấn đề này và nhiều hơn thế nữa. Đây là một công cụ mạnh mẽ, phổ quát và linh hoạt, và những kiến thức cơ bản về Regex sẽ đưa bạn đi rất xa trong thế giới công nghệ. Tại tinmoicongnghe.com, chúng tôi tin rằng việc nắm vững Regex là một kỹ năng thiết yếu, giúp tối ưu hóa công việc hàng ngày của bạn với dữ liệu và văn bản.
Regex là gì? Sức mạnh của biểu thức chính quy
Regex là một ngôn ngữ khớp mẫu; đó là một cách để mô tả một cách rõ ràng các mẫu khớp với chuỗi (ví dụ: từ hoặc câu). Chẳng hạn, giả sử bạn đang tìm kiếm một hình ảnh tên là foo trên ổ cứng, nhưng bạn không nhớ đó là tệp JPEG hay PNG. Bạn có thể sử dụng Regex với lệnh fd như sau: fd 'foo\.(jpg|png)'. Lệnh này sẽ tìm tất cả các tệp có tên “foo” và đuôi “.jpg” hoặc “.png”.
Nhiều tiện ích và ứng dụng công nghệ phổ biến sử dụng Regex để tìm kiếm, chuyển đổi và tương tác với văn bản. Ví dụ điển hình bao gồm grep -E [regex], find -regex [regex] hoặc fd [regex]. Việc sử dụng Regex cho phép bạn cực kỳ chính xác trong các tác vụ tìm kiếm và xử lý dữ liệu.
Regex được sử dụng rộng rãi khắp mọi nơi, từ các trang web trên internet cho đến các tiện ích và ứng dụng quen thuộc như ripgrep, Vim, Neovim, Emacs và vô số công cụ khác. Nắm vững Regex không chỉ giúp bạn làm việc hiệu quả hơn với dòng lệnh Linux mà còn mở ra cánh cửa để tương tác sâu hơn với nhiều hệ thống và ngôn ngữ lập trình.
 Mô tả về Regex trên màn hình terminal Linux.
Mô tả về Regex trên màn hình terminal Linux.
Các “Flavor” của Regex: Sự đa dạng và những điểm chung
Regex có nhiều “flavor” (phương ngữ) khác nhau, về cơ bản có nghĩa là các bộ quy tắc (cú pháp) khác nhau. Có rất nhiều flavor, nhưng chúng chỉ khác biệt ở những điểm nhỏ. Nếu bạn tuân thủ các khái niệm cơ bản mà chúng tôi sẽ đề cập sau, chúng sẽ hoạt động trên hầu hết các flavor và tiện ích Linux. Bạn không cần phải suy nghĩ quá nhiều về điều này khi mới bắt đầu.
PCRE (Perl Compatible Regular Expressions) là flavor đầy đủ tính năng nhất và được sử dụng rộng rãi. Tất cả các ví dụ trong bài viết này đều cố gắng tương thích với PCRE, đảm bảo tính ứng dụng cao nhất cho độc giả.
Khi bạn đã trở nên thành thạo, bạn có thể tham khảo bài viết của Wikipedia so sánh các flavor Regex hoặc bảng so sánh Regex toàn diện để tìm hiểu sâu hơn. Điều quan trọng cần nhớ là các khái niệm bạn sẽ học ở đây có thể áp dụng ở mọi nơi, làm nền tảng vững chắc cho mọi công việc liên quan đến biểu thức chính quy.
Tổng quan nhanh về các khái niệm Regex cốt lõi
Danh sách sau đây sẽ nhẹ nhàng giới thiệu cho bạn các tính năng Regex phổ biến:
| Khái niệm | Mô tả |
|---|---|
| Lớp ký tự | Một danh sách các ký tự cụ thể mà bạn muốn khớp, ví dụ: [abc]. |
| Nhóm bắt | Dấu ngoặc tròn bao quanh các phần liên quan của biểu thức, giống như dấu ngoặc trong toán học, ví dụ: (foo). |
| Bộ sửa đổi | Thay đổi cách thức hoạt động của biểu thức, ví dụ: phân biệt chữ hoa chữ thường. |
| Neo | Xác định điểm bắt đầu và kết thúc của một chuỗi hoặc dòng, ví dụ: ^foo$. |
| Định lượng | Cho biết số lượng, ví dụ: foo+, foo{3}, v.v. |
| Thay thế | Đơn giản là một câu lệnh “hoặc” (OR), ví dụ: foo|bar. |
| Ký tự đại diện DOTALL | Khớp mọi thứ, giống như một ký tự đại diện—chỉ là một dấu chấm đơn. |
Bạn sẽ kết hợp các tính năng này để mô tả một mẫu tìm kiếm mạnh mẽ và chính xác. Lưu ý rằng một số tính năng này chỉ hoạt động với các cờ lệnh cụ thể (modifiers) được đề cập sau này. Ví dụ: grep -P foo để kích hoạt chế độ PCRE.
Ký tự đại diện DOTALL: Khớp mọi thứ
Ký tự đại diện DOTALL (thường là dấu chấm .) giống như một ký tự wildcard vì nó khớp với mọi thứ (trừ ký tự xuống dòng mặc định trong một số flavor, nhưng có thể thay đổi bằng modifier). Bạn sẽ thường xuyên sử dụng ký tự này ở những nơi bạn muốn khớp bất kỳ ký tự nào.
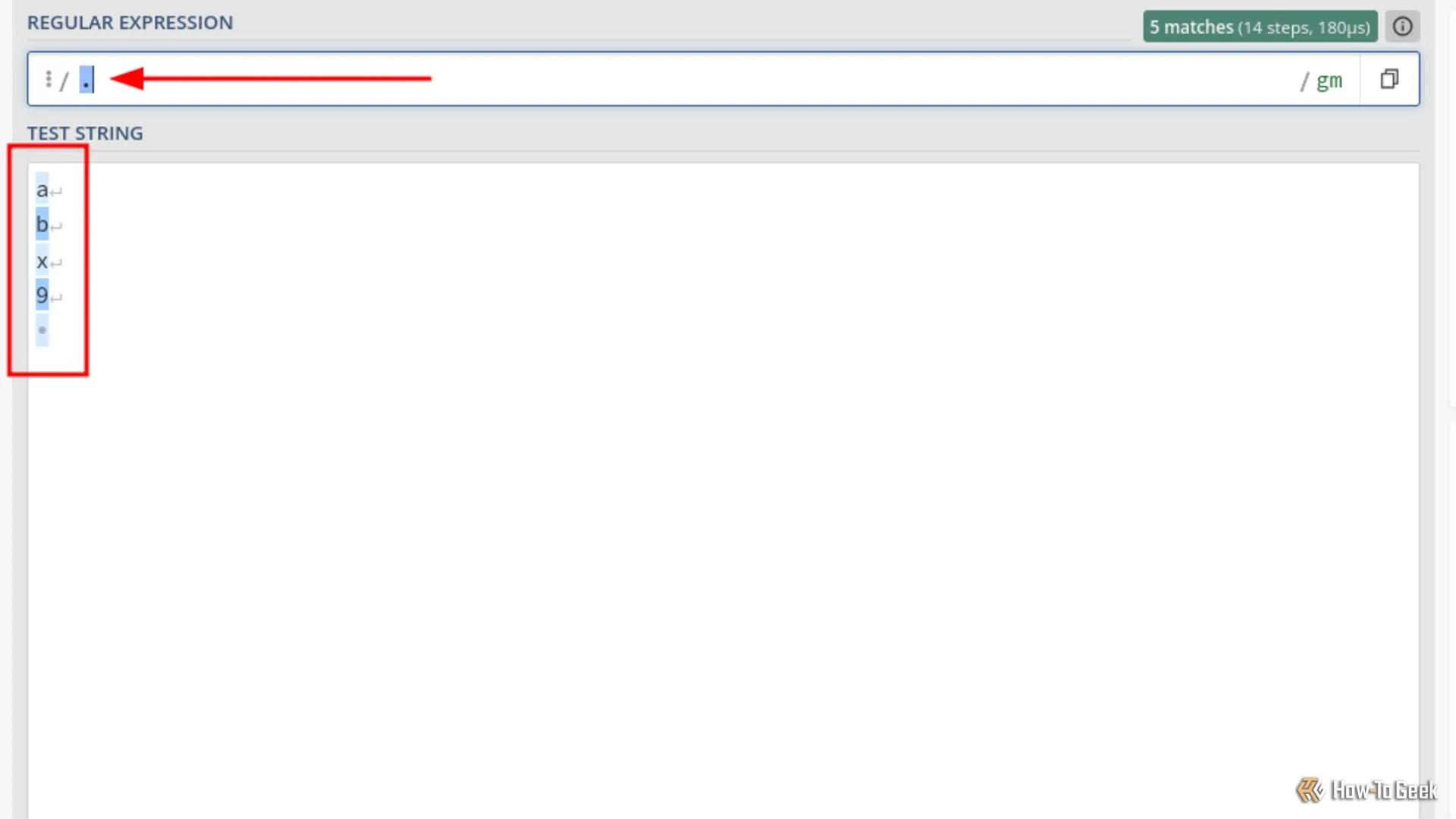 Ví dụ sử dụng ký tự đại diện DOTALL trong Regex khớp với nhiều dòng văn bản.
Ví dụ sử dụng ký tự đại diện DOTALL trong Regex khớp với nhiều dòng văn bản.
Lớp ký tự (Character Classes): Khớp các ký tự cụ thể trong bất kỳ thứ tự nào
Lớp ký tự là một danh sách các ký tự, được đặt trong dấu ngoặc vuông [], mà bạn muốn khớp. Ví dụ, biểu thức sau sẽ khớp với a, b, z, 1, 2, hoặc 9:
[abz129]Biểu thức này khớp với bất kỳ ký tự chữ và số nào, chữ hoa hoặc chữ thường:
[a-zA-Z0-9]Dấu gạch nối (-) có ý nghĩa đặc biệt trong một lớp ký tự để chỉ một dải ký tự (ví dụ: a-z). Vì vậy, nếu bạn muốn khớp nó theo nghĩa đen, bạn phải đặt nó ở đầu [-a-z] hoặc thoát nó [a-z\-].
Điều quan trọng cần hiểu là một lớp ký tự chỉ khớp chính xác một ký tự, trừ khi bạn sử dụng một bộ định lượng (quantifier) (sẽ được đề cập sau).
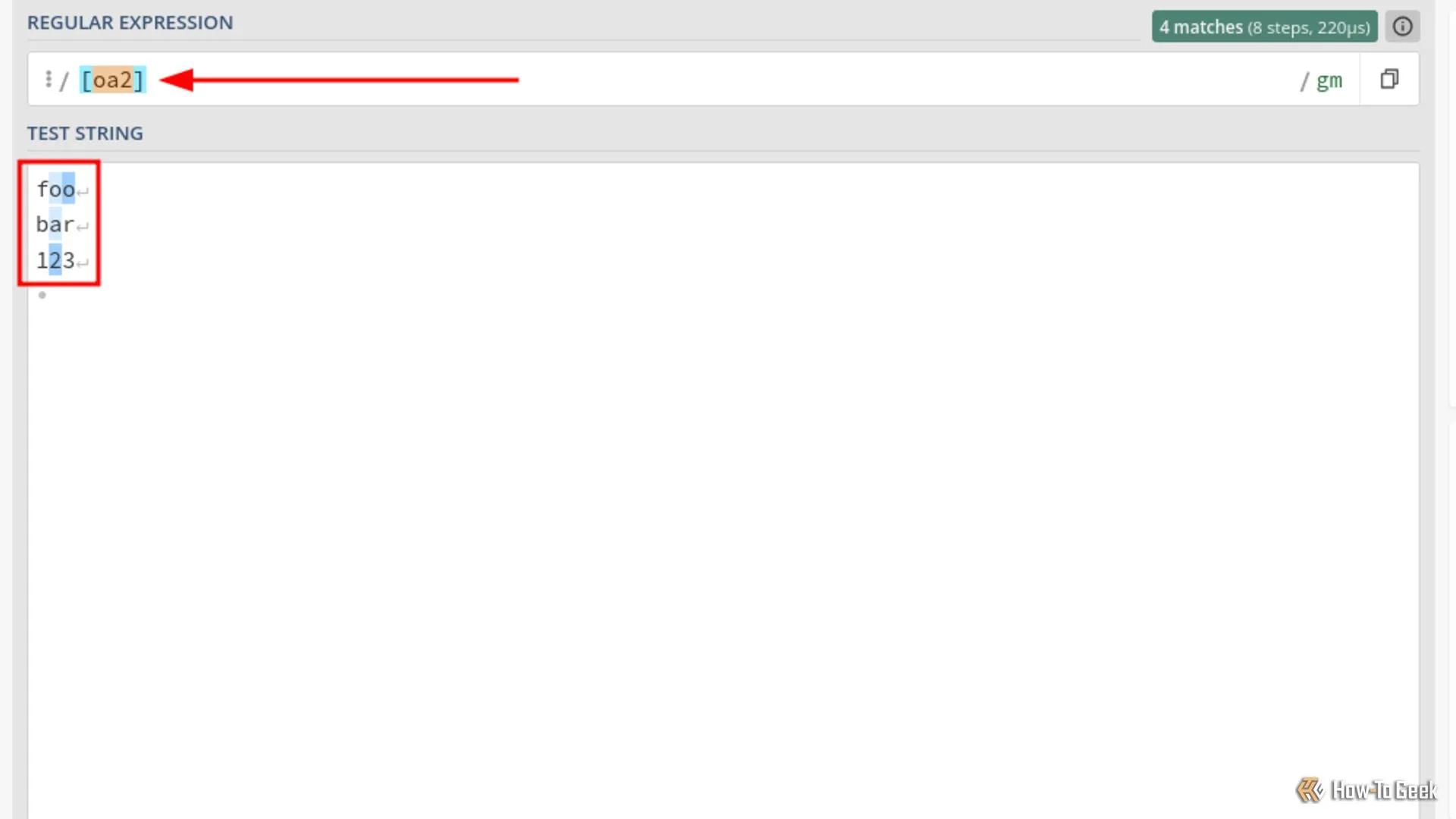 Minh họa lớp ký tự Regex khớp với các ký tự cụ thể trong kết quả tìm kiếm.
Minh họa lớp ký tự Regex khớp với các ký tự cụ thể trong kết quả tìm kiếm.
Trong hộp kết quả, bạn có thể thấy nhiều ký tự được tô sáng. Mỗi khớp tương ứng với một trong các ký tự trong lớp ký tự. Nếu bạn nhìn kỹ vào hộp kết quả trong hình ảnh, bạn sẽ thấy rằng một lớp ký tự duy nhất khớp với nhiều ký tự. Chế độ toàn cục (g – global mode) chịu trách nhiệm cho điều này. Chế độ toàn cục có nghĩa là Regex không dừng lại ở lần khớp đầu tiên mà tiếp tục và tạo ra nhiều lần khớp.
Nhóm bắt (Match Groups): Phân định ranh giới biểu thức con
Theo một cách nào đó, nhóm bắt (match groups) tương tự như dấu ngoặc tròn trong toán học. Ví dụ, khi bạn viết một biểu thức toán học như 1 + (2 / 2), nó khác với (1 + 2) / 2. Phép tính bắt đầu với dấu ngoặc tròn trong cùng, điều này làm thay đổi kết quả.
Dấu ngoặc tròn trong Regex hoạt động như ranh giới; chúng nhóm các phần của biểu thức lại với nhau. Ví dụ, foo(bar|baz) không giống như foobar|baz, bởi vì cái trước sẽ khớp foobar hoặc foobaz; cái sau sẽ khớp foobar hoặc baz. Điều này cho thấy tầm quan trọng của việc nhóm các phần tử trong Regex để kiểm soát thứ tự ưu tiên và phạm vi khớp.
Định lượng (Quantifiers): Cách chỉ định số lượng chính xác và biến đổi
Định lượng (quantifiers) cho phép chúng ta xác định số lượng. Khi chúng ta khớp một ký tự với DOTALL hoặc lớp ký tự, chúng ta sử dụng định lượng để nói rõ có bao nhiêu. Chúng ta cũng có thể áp dụng định lượng cho các nhóm bắt, vì vậy chúng ta có thể xác định số lượng cho toàn bộ biểu thức.
Khớp không hoặc nhiều lần với dấu sao (*)
Ký tự đại diện dấu sao (*) sẽ khớp không hoặc nhiều thứ. Điều này có nghĩa là nó sẽ khớp với 0 lần xuất hiện của ký tự hoặc nhóm trước đó, hoặc nhiều lần xuất hiện. Ví dụ, biểu thức sau khớp a, b, z, hoặc một chuỗi rỗng:
[abz]*Khớp một hoặc nhiều lần với dấu cộng (+)
Ký tự đại diện dấu cộng (+) sẽ khớp một hoặc nhiều thứ. Điều này có nghĩa là nó yêu cầu ít nhất một lần xuất hiện của ký tự hoặc nhóm trước đó. Biểu thức sau khớp một hoặc nhiều ký tự a, b, hoặc z:
[abz]+Làm cho tùy chọn với dấu hỏi (?)
Ký tự đại diện dấu hỏi (?) làm cho mục trước đó trở thành tùy chọn. Nó sẽ khớp với 0 hoặc 1 lần xuất hiện của ký tự hoặc nhóm trước đó. Biểu thức sau sẽ khớp chính xác một a, b, z, hoặc hoàn toàn không có gì:
[abz]?Xác định số lượng chính xác với dấu ngoặc nhọn ({})
Dấu ngoặc nhọn cho phép chúng ta xác định một số lượng chính xác. Ví dụ, biểu thức sau sẽ khớp a, b, hoặc z chính xác hai lần:
[abz]{2}Biểu thức sau sẽ khớp a, b, hoặc z từ 2 đến 4 lần:
[abz]{2,4}Tóm tắt các Định lượng
?: Tùy chọn (0 hoặc 1 lần).*: Không hoặc nhiều (0 hoặc nhiều lần, bao gồm chuỗi rỗng).+: Một hoặc nhiều (1 hoặc nhiều lần).{n,m}: Khớp từ n đến m lần.
Lưu ý rằng các ký tự đại diện dấu cộng (+) và dấu hỏi (?) không hoạt động với hầu hết các tiện ích Linux trừ khi bạn sử dụng các cờ lệnh phù hợp. Các cờ này sẽ được đề cập chi tiết hơn trong phần tiếp theo.
Định lượng tham lam (Greedy) và lười biếng (Lazy): Khớp nhiều hay ít tùy ý
Một số định lượng cho phép chúng ta xác định một số lượng không xác định. Ví dụ, dấu cộng (+) có nghĩa là một hoặc nhiều—bất kỳ giá trị nào lớn hơn 0. Các ký tự đại diện dấu cộng (+) và dấu sao (*) theo mặc định là tham lam (greedy), có nghĩa là chúng cố gắng khớp càng nhiều càng tốt. Ngược lại, chúng ta có thể làm cho chúng lười biếng (lazy) để chúng khớp càng ít càng tốt.
Việc thêm dấu hỏi (?) vào sau một định lượng sẽ làm cho nó trở nên lười biếng. Ví dụ, biểu thức sau sẽ khớp a, b, hoặc z, nhưng nó sẽ dừng lại sau lần khớp đầu tiên (nó lười biếng):
[abz]+?Ký tự đại diện dấu sao (*) cũng tương tự, ngoại trừ một chi tiết nhỏ: nó khớp không hoặc nhiều mục. Lần khớp lười biếng nhất có thể là không, vì vậy biểu thức sau sẽ không khớp gì cả:
[abz]*?Việc làm cho một định lượng trở nên lười biếng có thể hiệu quả hơn vì nó không cần xử lý toàn bộ chuỗi. Nếu bạn đang tìm kiếm trong hàng triệu chuỗi, việc chỉ khớp vài ký tự đầu tiên có thể tiết kiệm rất nhiều thời gian và tài nguyên. Đây là một kỹ thuật tối ưu hóa quan trọng trong Regex.
Neo (Anchors): Khớp đầu và cuối dòng
Neo (Anchors) rất đơn giản để hiểu. Có hai loại: một loại chỉ ra điểm bắt đầu của một dòng (^) và một loại chỉ ra điểm kết thúc của một dòng ($). Mẫu sau khớp foo chính xác và không có gì khác:
^foo$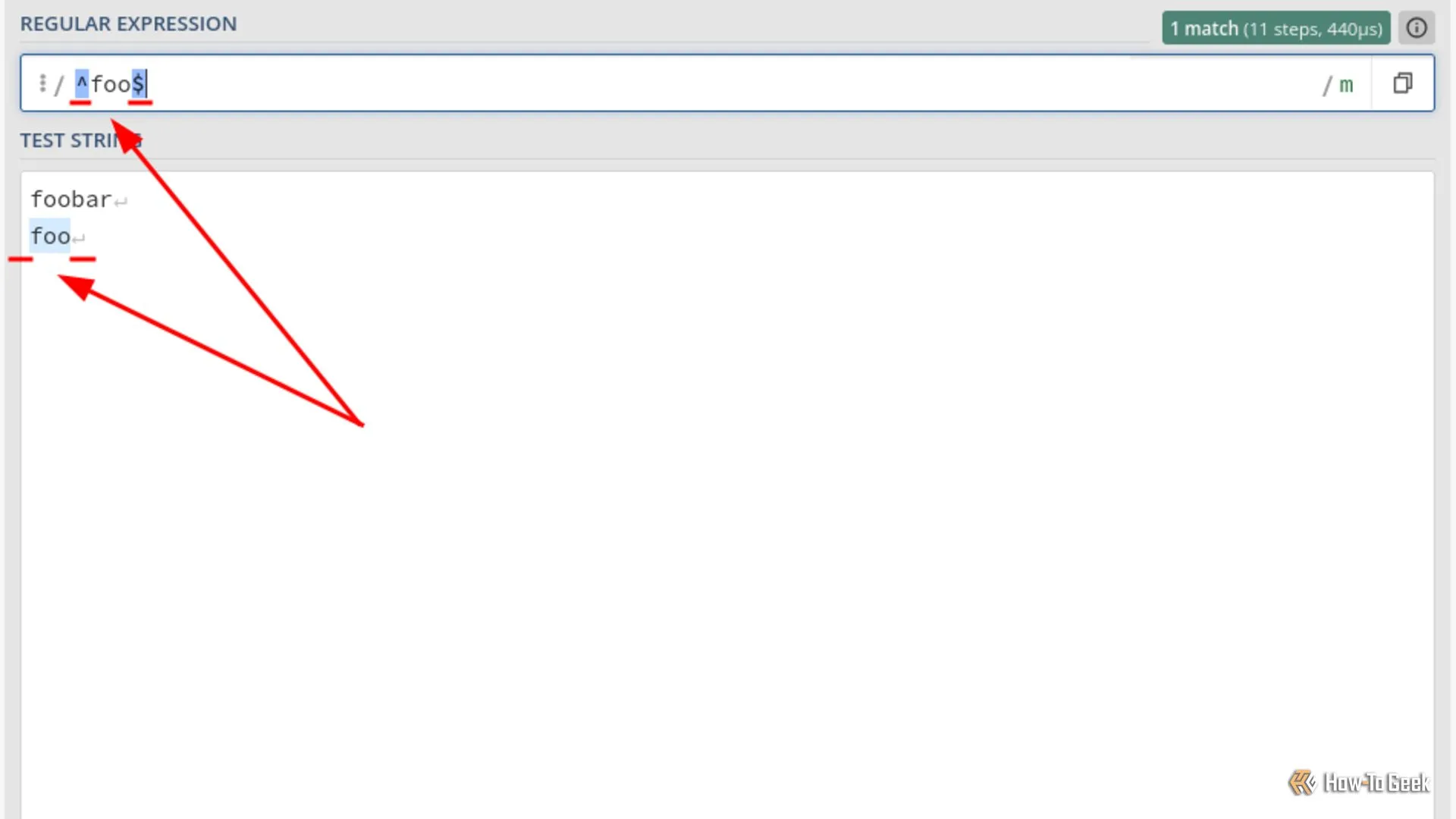 Ví dụ về Anchors trong Regex giúp khớp chính xác từ khóa "foo" ở đầu và cuối dòng.
Ví dụ về Anchors trong Regex giúp khớp chính xác từ khóa "foo" ở đầu và cuối dòng.
Bộ sửa đổi (Modifiers): Các cờ thay đổi cách hoạt động của Regex
Bộ sửa đổi (Modifiers) là một cách để thay đổi cách Regex hoạt động. Ví dụ, chúng ta có thể làm cho nó phân biệt chữ hoa chữ thường hoặc không. Chúng ta đã xem xét bộ sửa đổi toàn cục (global modifier), nhưng đáng để nhắc lại rằng chúng là các cờ thường nằm ở cuối một biểu thức hoặc được truyền dưới dạng tùy chọn cho công cụ Regex.
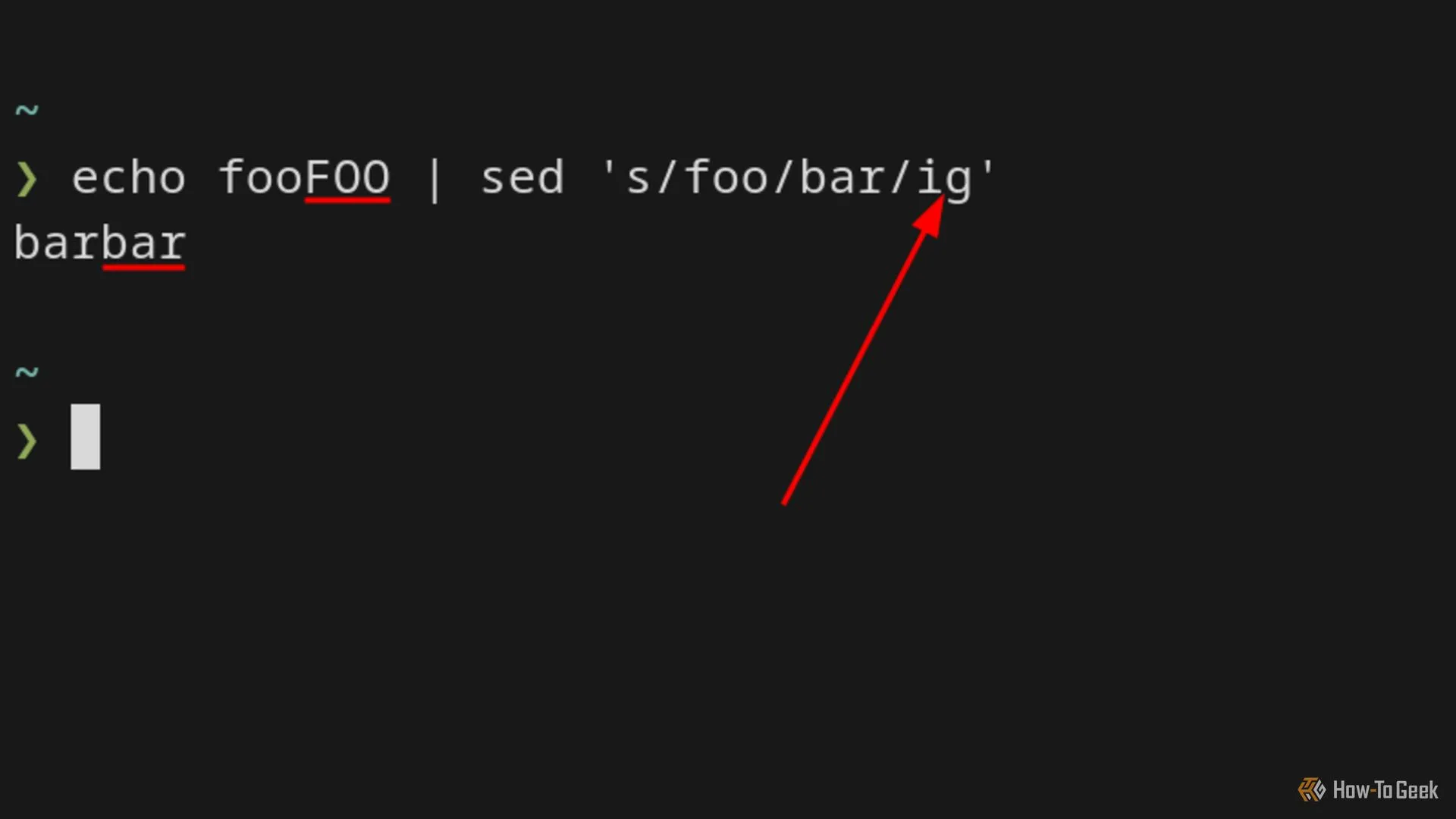 Sử dụng modifier 'i' trong lệnh sed để thay thế không phân biệt chữ hoa chữ thường.
Sử dụng modifier 'i' trong lệnh sed để thay thế không phân biệt chữ hoa chữ thường.
Bộ sửa đổi Toàn cục (Global Modifier)
Bộ sửa đổi toàn cục (g) cho phép Regex tiếp tục tìm kiếm các lần khớp sau khi nó tìm thấy lần khớp đầu tiên, dẫn đến nhiều lần khớp. Ngược lại, việc tắt bộ sửa đổi toàn cục sẽ khiến Regex dừng lại sau khi tìm thấy lần khớp đầu tiên.
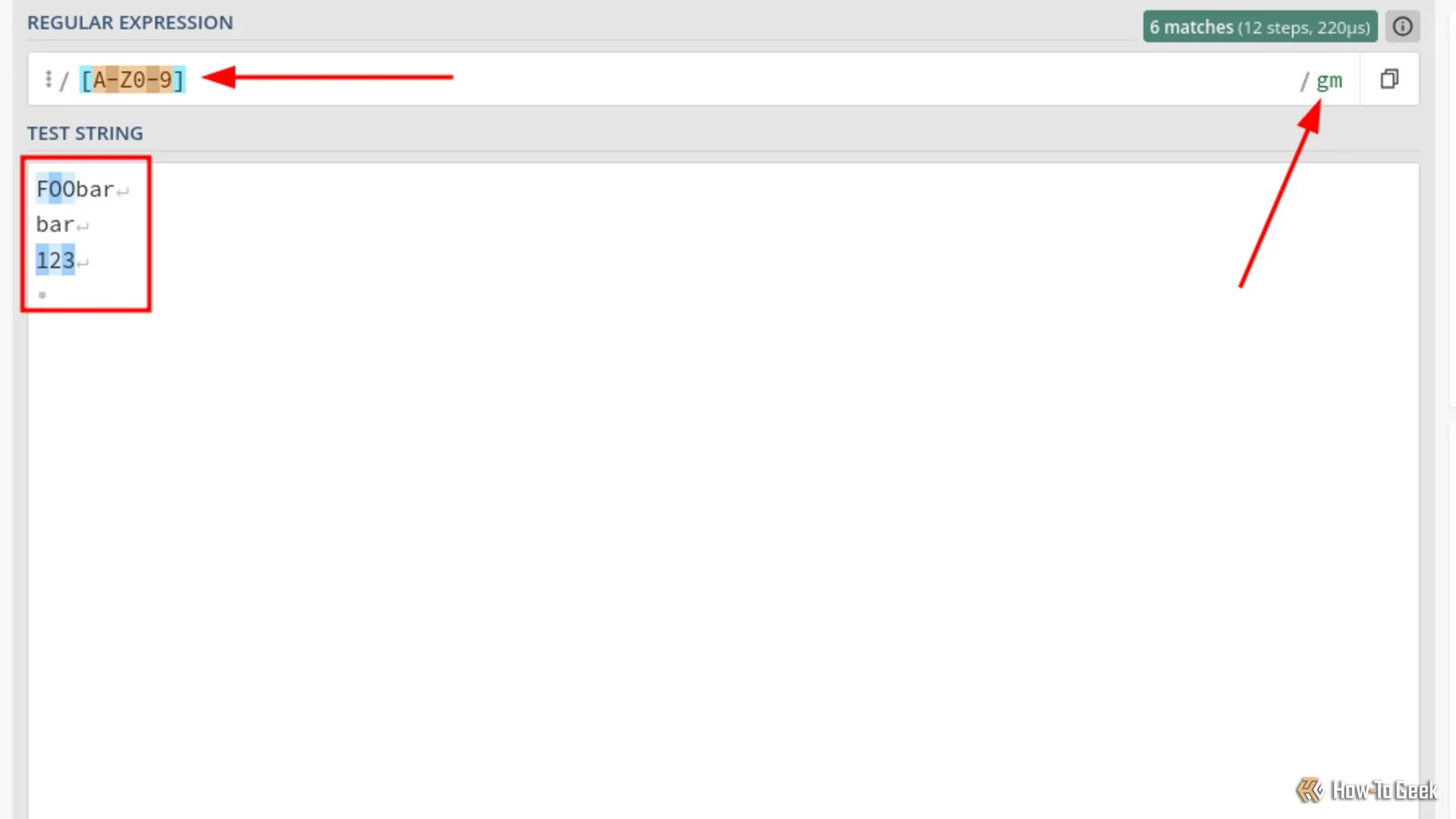 Minh họa Global Modifier (g) trong Regex, cho phép tìm kiếm nhiều khớp cho các ký tự hoa và số.
Minh họa Global Modifier (g) trong Regex, cho phép tìm kiếm nhiều khớp cho các ký tự hoa và số.
Biểu thức này khớp các chữ cái viết hoa và số riêng lẻ. Nó bỏ qua các chữ cái viết thường. Vì bộ sửa đổi toàn cục (g) được kích hoạt, nó khớp nhiều mục.
Bộ sửa đổi Không phân biệt chữ hoa chữ thường (Case Insensitivity Modifier)
Bộ sửa đổi không phân biệt chữ hoa chữ thường (i) sẽ khớp với cả chữ hoa và chữ thường khi được kích hoạt. Điều này cực kỳ hữu ích khi bạn không chắc chắn về cách viết hoa của chuỗi bạn đang tìm kiếm hoặc muốn tìm kiếm một cách linh hoạt hơn.
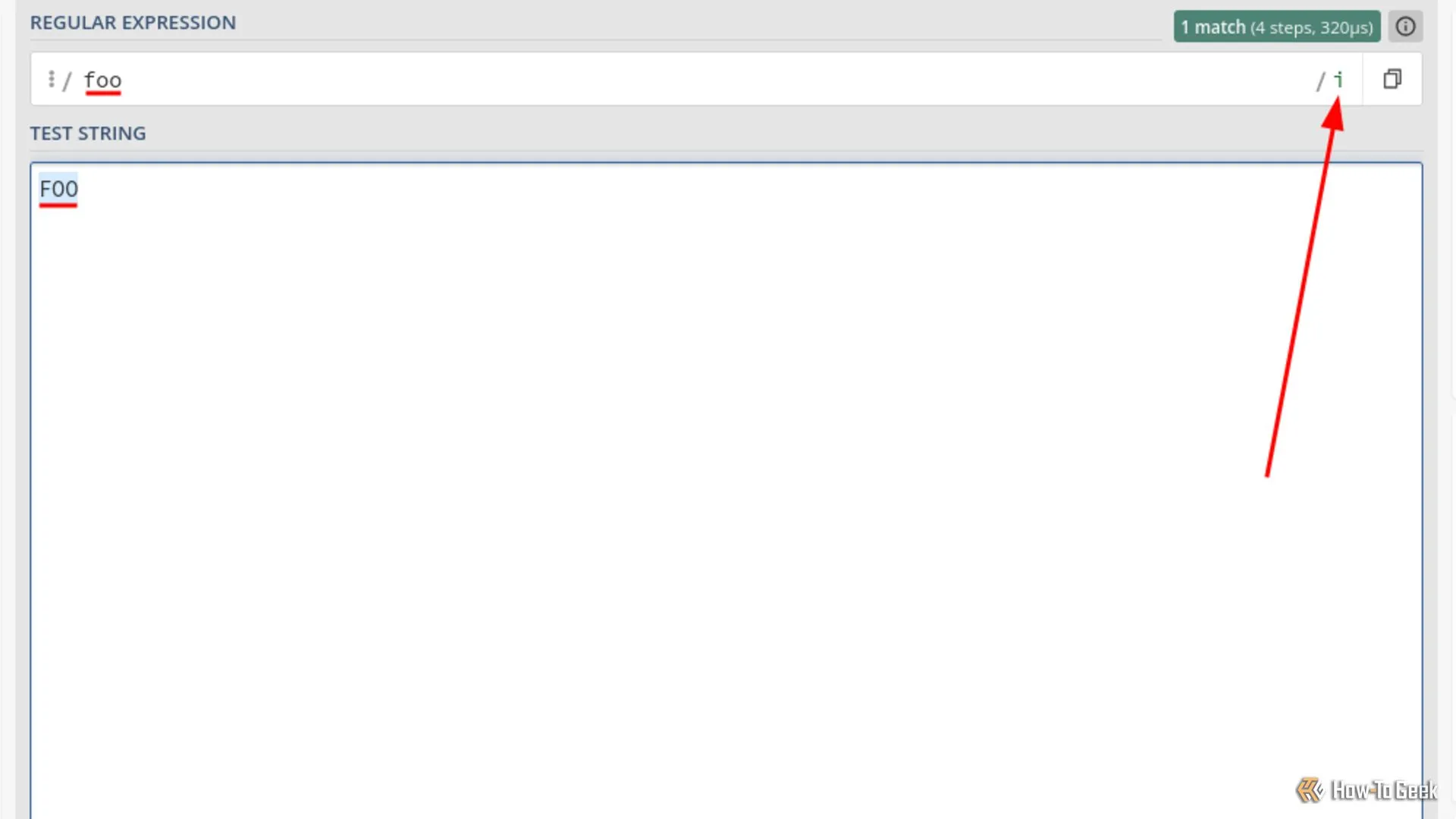 Ví dụ cụ thể về Case Insensitivity Modifier (i) giúp Regex khớp từ "foo" không phân biệt chữ hoa, chữ thường.
Ví dụ cụ thể về Case Insensitivity Modifier (i) giúp Regex khớp từ "foo" không phân biệt chữ hoa, chữ thường.
Bộ sửa đổi Đa dòng (Multiline Modifier)
Các neo xác định điểm bắt đầu (^) và kết thúc ($) của một chuỗi. Khi bộ sửa đổi đa dòng (m) được kích hoạt, các neo sẽ khớp điểm bắt đầu và kết thúc của mỗi dòng. Khi nó không hoạt động, các neo sẽ khớp toàn bộ chuỗi.
Đây là cách các neo hoạt động khi chế độ đa dòng được kích hoạt:
^foo$
^bar$Và khi nó không hoạt động:
^foobars$Để đánh giá tất cả các dòng khi bộ sửa đổi đa dòng (m) được kích hoạt, bạn cũng phải bật bộ sửa đổi toàn cục (g). Nhưng hãy nhớ rằng việc làm như vậy cũng sẽ tạo ra nhiều lần khớp.
Tổng hợp: Sử dụng Regex với các lệnh dòng lệnh
Bây giờ là phần quan trọng nhất: làm thế nào để chúng ta áp dụng những gì đã học vào thực tế? Như đã đề cập ở đầu bài, find, fd, grep, ripgrep và sed đều hỗ trợ Regex. Hãy chú ý đến các cờ lệnh mà chúng tôi sử dụng; chúng được chọn để sử dụng các flavor Regex tương tự nhau.
Đối với mỗi lệnh, chúng ta sẽ sử dụng biểu thức sau:
^.+/[fo]+.(jpg|png)$Mẫu này khớp một đường dẫn POSIX cho một tệp JPG hoặc PNG. Ví dụ:
/foo/bar/baz/foo.jpgBiểu thức này bao gồm mọi thứ chúng ta đã học: neo, lớp ký tự, định lượng, thay thế, nhóm bắt và ký tự đại diện DOTALL. Dưới đây là tóm tắt biểu thức (theo thứ tự xuất hiện):
| Phân đoạn | Ghi chú |
|---|---|
^ |
Khớp điểm bắt đầu của dòng. |
.+ |
Khớp bất kỳ ký tự nào, một hoặc nhiều lần. |
/ |
Khớp một dấu gạch chéo ngược (/) ngay trước tên tệp. Dấu gạch chéo nghĩa đen này định nghĩa một ranh giới rõ ràng cho tên tệp của chúng ta, và DOTALL trước đó sẽ khớp tất cả các ký tự đường dẫn khác (bao gồm cả dấu gạch chéo). |
[fo]+ |
Khớp các chữ cái f và o một hoặc nhiều lần, ví dụ: fo, foo, ffoo, fffooo, fofofof. |
. |
Khớp một dấu chấm nghĩa đen (không phải DOTALL). |
(jpg|png) |
Một nhóm bắt; chúng ta đã sử dụng nó ở đây để nhóm hai mẫu này lại với nhau. Dấu gạch đứng (|) được gọi là thay thế, và sử dụng nó như thế này có nghĩa là jpg hoặc png. |
$ |
Khớp điểm kết thúc của dòng. |
Chúng ta sẽ khớp tất cả các biểu thức với một tệp (gọi là examples) với nội dung sau:
/foo/bar/baz/foo.jpg
/one/two/thr/foo.png
<p>/this/should/not/match.jpg</p>Đối với các lệnh find, chúng ta sẽ tạo các tệp như vậy trong hệ thống tệp của mình và tìm kiếm chúng.
Sử dụng grep với Regex
Đối với grep, chúng ta phải sử dụng cờ -P, nó kích hoạt công cụ PCRE (Perl Compatible Regular Expressions) (phiên bản giới hạn của nó). PCRE là flavor rộng rãi nhất và hỗ trợ gần như mọi tính năng bạn có thể nghĩ đến.
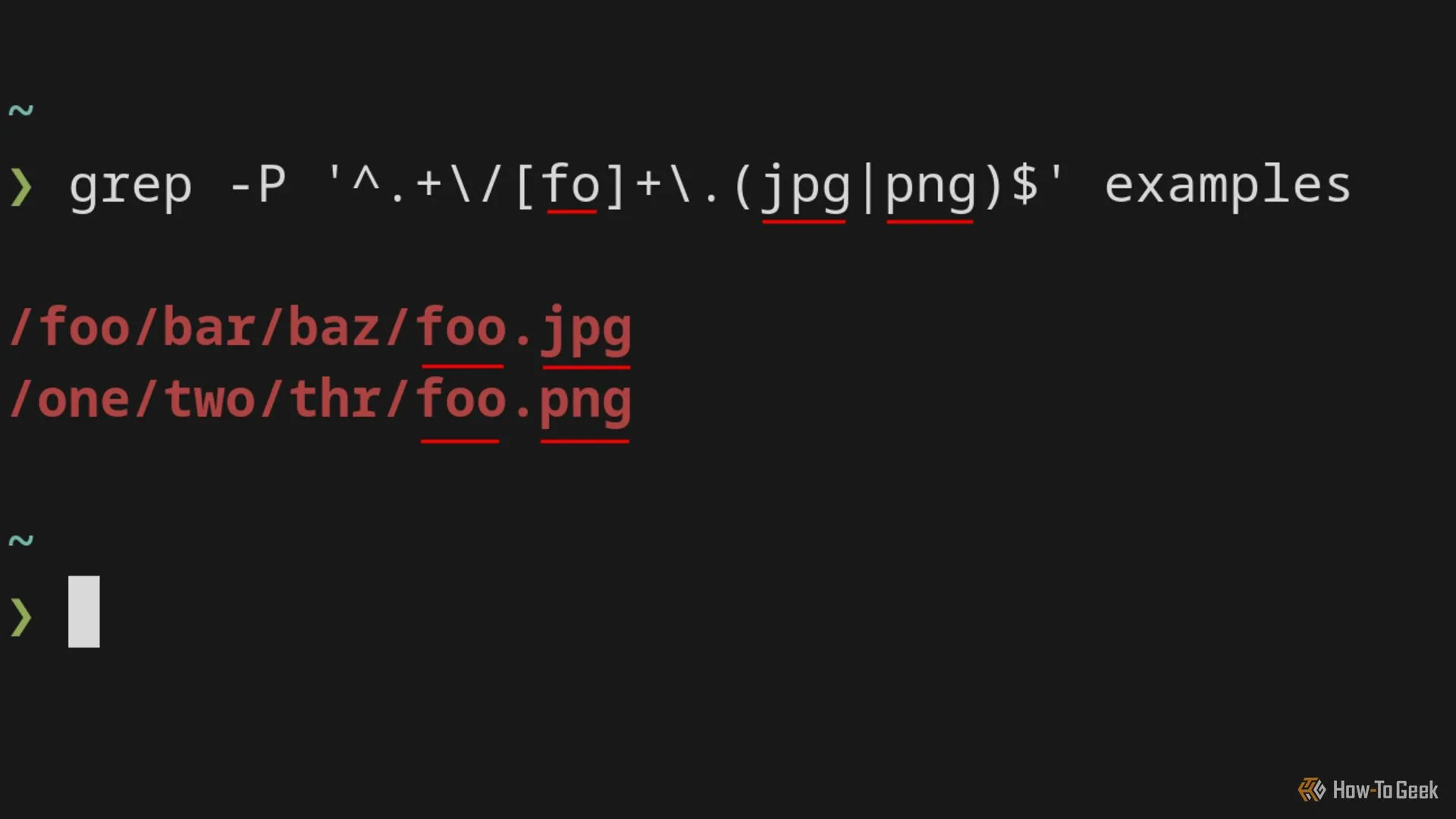 Lệnh grep với cờ -P hiển thị các đường dẫn tệp khớp với mẫu Regex PCRE.
Lệnh grep với cờ -P hiển thị các đường dẫn tệp khớp với mẫu Regex PCRE.
Nếu bạn chưa quen với grep, hãy tham khảo hướng dẫn chi tiết về cách sử dụng nó để tìm kiếm văn bản trong Linux.
Sử dụng find với Regex
Lệnh find hỗ trợ nhiều flavor Regex. Bạn có thể xem danh sách chúng với lệnh sau:
find -regextype helpFlavor khớp gần nhất với PCRE là posix-extended, hay còn gọi là POSIX ERE (Extended Regular Expressions). POSIX ERE thiếu nhiều tính năng nâng cao, nhưng nó hỗ trợ tất cả các tính năng chúng ta đã đề cập.
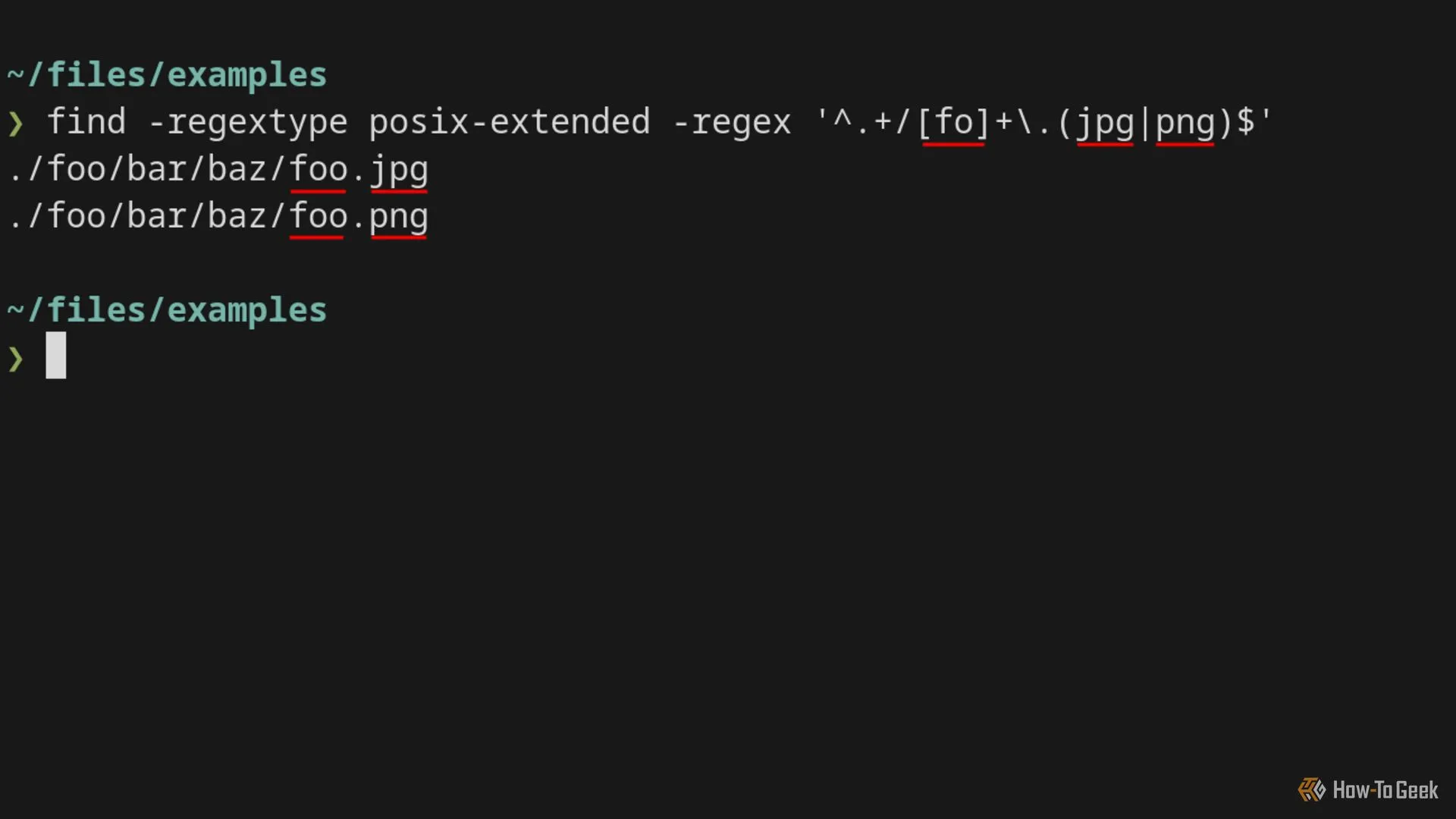 Lệnh find với cờ -regex và -regextype hiển thị các đường dẫn tệp đã tìm thấy khớp với Regex.
Lệnh find với cờ -regex và -regextype hiển thị các đường dẫn tệp đã tìm thấy khớp với Regex.
Nếu lệnh này có vẻ dài dòng, bạn nên sử dụng alias để đặt các tùy chọn Regex theo mặc định, giúp tiết kiệm thời gian và công sức.
Sử dụng fd với Regex
Lệnh fd sử dụng Rust crate regex (một gói Rust). Crate regex gần như tương thích hoàn toàn với PCRE, vì vậy chúng ta có thể sử dụng nó mà không cần quá lo lắng. Tuy nhiên, theo mặc định, fd chỉ khớp với tên tệp, vì vậy chúng ta phải sử dụng cờ --full-path nếu muốn khớp với toàn bộ đường dẫn tệp.
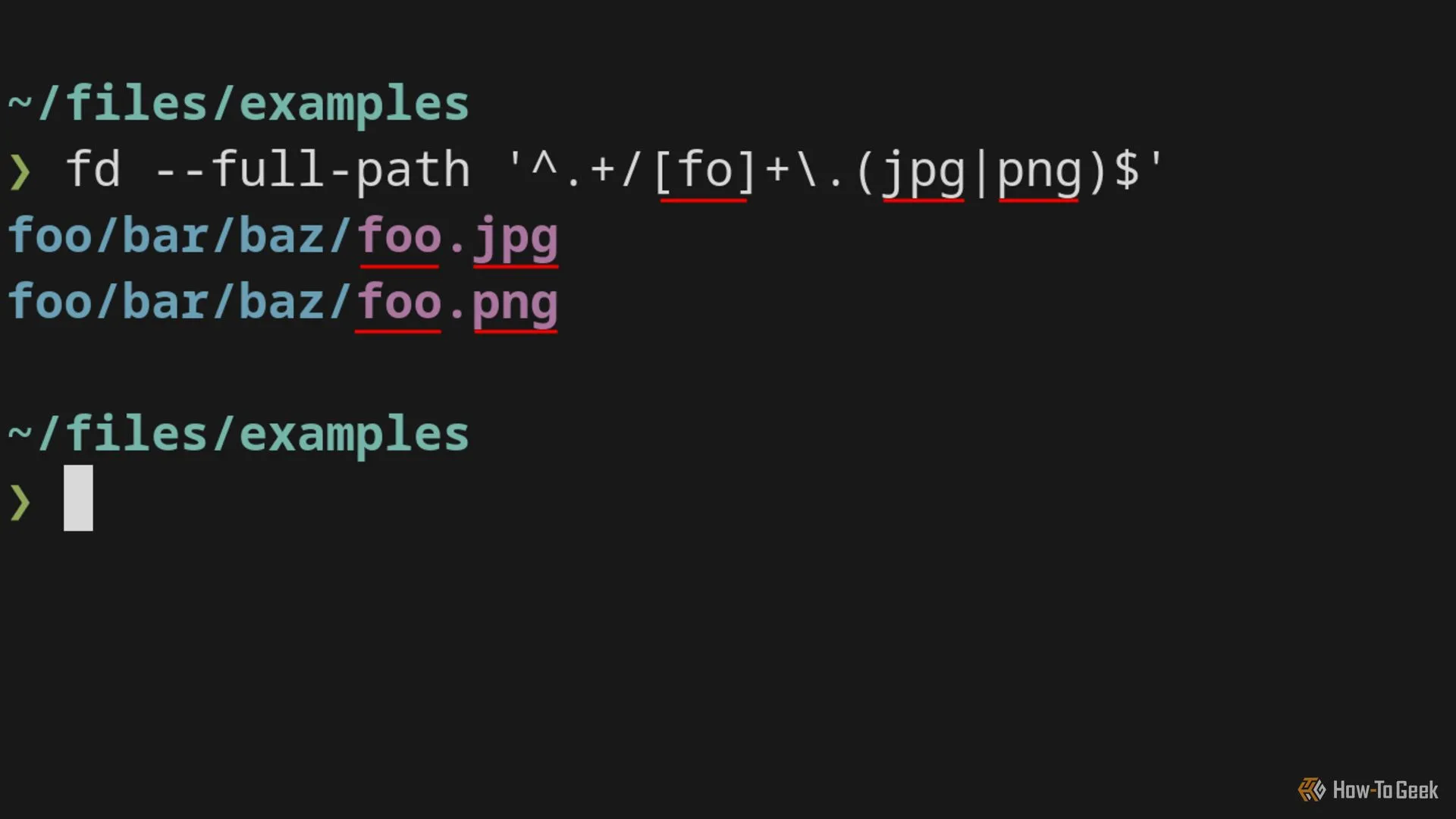 Kết quả từ lệnh fd tìm kiếm và khớp các đường dẫn tệp sử dụng biểu thức chính quy.
Kết quả từ lệnh fd tìm kiếm và khớp các đường dẫn tệp sử dụng biểu thức chính quy.
Sử dụng ripgrep với Regex
Sử dụng Regex với lệnh ripgrep rất đơn giản vì nó cũng sử dụng Rust crate regex. Như đã đề cập trước đó, Rust crate này khớp chặt chẽ với PCRE, mang lại hiệu suất và tính năng vượt trội.
Sử dụng sed với Regex
Lệnh sed khác với các lệnh khác; nó cho phép chúng ta tìm kiếm và thay thế chuỗi. Nếu bạn chưa quen với nó, bạn nên xem hướng dẫn tuyệt vời về cách sử dụng lệnh sed trên Linux. Dạng tổng quát của lệnh như sau:
s/pattern/replacement/Không nhất thiết phải sử dụng dấu gạch chéo ngược, vì bạn có thể sử dụng bất kỳ ký tự nào bạn muốn làm dấu phân cách. Trong ví dụ dưới đây, chúng ta đã sử dụng ký tự dấu gạch đứng (|) thay vì dấu gạch chéo ngược để không làm sed nhầm lẫn. Sử dụng dấu gạch đứng có nghĩa là chúng ta không cần phải thoát các dấu gạch chéo ngược trong giá trị thay thế được cung cấp (một đường dẫn).
Đối với sed, chúng ta cần sử dụng flavor Regex GNU ERE, và chúng ta thực hiện điều đó với cờ -E. Mọi thứ hoạt động trong GNU ERE sẽ hoạt động trong PCRE, điều này rất tốt cho chúng ta.
Trong ví dụ, chúng ta đã trích xuất các kết quả và thay thế các đường dẫn tệp, tương tự như cách cat và grep hoạt động, nhưng sed cũng hỗ trợ chỉnh sửa tại chỗ thông qua cờ -i.
Kết luận
Đó là những kiến thức cơ bản về Regex – Biểu thức chính quy. Những kiến thức nền tảng này sẽ đưa bạn đi rất xa trong hành trình làm việc với văn bản và dữ liệu. Điều quan trọng cần nhớ là nhiều tiện ích sử dụng các flavor Regex khác nhau, và vì vậy, nếu bạn đi chệch khỏi các cờ lệnh đã đề cập, bạn có thể thấy rằng một số tính năng không hoạt động.
Ngoài ra, Regex là thứ bạn cần thực hành trực tiếp trước khi nó thực sự có ý nghĩa. Bạn có thể rèn luyện kỹ năng của mình, có được cái nhìn sâu sắc và tìm hiểu thêm qua regex101, một sân chơi trực tuyến mạnh mẽ cung cấp các mẹo và hướng dẫn chi tiết. Hãy bắt đầu khám phá sức mạnh của Regex ngay hôm nay để tối ưu hóa công việc và nâng cao hiệu suất làm việc với công nghệ của bạn! Chia sẻ ý kiến hoặc kinh nghiệm của bạn về Regex dưới phần bình luận để cùng tinmoicongnghe.com xây dựng một cộng đồng công nghệ vững mạnh.